Argonauta 3: 19-29 (2000)
parametricsとnonparametrics
parametricsとnonparametricsは統計検定を二分する方法論で、生態学関係の論文でも共によく使われている。この両者の区別については、これまで以下のような見方が一般的だったのではないかと筆者は理解している。つまり、parametricsは母集団の正規分布や、比較するサンプル集団相互の分散や相等性を要件とするのに対し、nonparametricsは多少検出力は落ちるものの母集団の分布に依存せず、それだけ生物データに使いやすい。つまり、後者はデータ次元だけの処理で済む便利な検定法、という認識である。ところが最近になって、一般にnonparametricsとされている検定法でも母集団分布に制限を持つものがあるという主張がみられるようになった。たとえばKramer & Schmidhammer (1992)は、従来nonparametricでdistribution free(母集団の分布に不依存)と考えられていたχ2検定が、理論的に特定の母集団分布を要求する手法であると述べている。またUnderwood (1997 p131)は、おなじくnonparametricsのMann-Whitney U検定について、サンプル集団間の分散不等の影響を避けるためにこの検定を用いるのはまちがいで、U検定の前提には、比較する標本集団の頻度分布形が同じというきびしい条件があると述べている。かと思うと逆に、本来条件が厳しいはずのparametricsのt検定で、標本数がほとんど等しければ、分散の違いはあまり問題にならない(Zar 1999 p128)ということも言われるようになった。
どの分野であれ学問は日進月歩、従来の知識がそのままで通用しなくなるのは当然だが、このparametricsとnonparametrics問題は、データ処理や研究計画に幅広く影響する。手法の適用条件についてある程度の確信を持っておかないと、論文化の際などに不安を抱えることになるだろう。そこで本稿では、「nonparametricsは母集団の分布を考えずに使えるのか」という点を中心に、parametricsとnonparametricsの使用における制限要因について考察した結果を述べ、またそれをふまえて若干の意見を呈示したい。
なお、この原稿を書くに当っては、栗原健夫、沼田英治、遊佐陽一各氏との議論及び三氏からの文献指示、提供に助けられた。以下に触れることの中には上記の人々から教えられたことも含まれている。ただし記述内容の最終的責任はむろん著者に属する。
'nonparametrics'の定義
parametricsとnonparametricsは生物検定の二つの流れ、と書いたが、これらは何を意味するのか。nonparametricsとはparametricsでないもの、という意味だから、parametricsがわかればnonparametricsもわかる理屈である。しかしparametricsはあまりにも標準的な方法であるためか、教科書類では特に定義されることなく解説されていることが多い。むしろnonparametricsが登場する時に、はじめてその差が明確になるという傾向がある。nonparametricsについては、たとえば以下のように書かれている。
- They are called nonparametric methods because their null hypothesis is not concerned with specific parameters (such as the mean in analysis of variance)
but only with the distribution of the variates(変量). (Sokal & Rohlf 1981 p429).
- A nonparametric statistical test is based on a model that specifies only very general conditions and none regarding the specific form of the distribution
from which the sample was drawn (Siegel & Castellan 1988 p34).
- 検定法の中で、その適用にあたり母集団の分布形に関して特別の仮定をおく必要がないものをノンパラメトリック検定または分布に依存しない検定(distribution free test)と呼ぶ(市原 1990 p11)。
- A large body of statistical methods is available that comprises procedures not requiring the estimation of the population variance or mean and not stating hypotheses about parameters. These testing procedures are termed nonparametric tests. As these methods also do not make assumptions about the nature of the distribution (e.g. normality) of the sampled populations (although they might assume that the sampled populations have the same dispersion or shape), they are sometimes referred to as distribution free test (Zar 1999 p145).
教科書類では、parametricsとしてはt検定、ANOVA、ピアソンの積率相関(いわゆる普通の相関係数)、多変量解析のPCAなどが、またnonparametricsとしてはMann-WhitneyのU検定、χ2検定、順位相関などが解説されるのが普通である。以上をふまえて、私は次のように単純に理解している。「parametricsとはparameterを使う検定という意味であり、この場合のparameterは平均と分散を意味する。平均と分散による検定は、母集団の正規分布を前提とする。従って、平均、分散、正規分布を使用ないし前提とする検定がparametrics、それ以外がnonparametricsとなる」。もし'parameter'を、母集団からの何らかの抽出指標というように広く取ると平均と分散に限らないことになるが、その場合はMann-WhitneyのU値、χ2検定のχ2、順位相関のτなど何でもparameterであるから、nonparametricsという概念にはほとんど意味がなくなる。問題はdistribution freeという言葉である。上の定義では、3と4でこの言葉が使われているが、文字通り分布がどうであってもよいとはっきり書いている例はない。2は比較的それに近いが,特定の分布に依存しないと言っているのみで、分布が何でもよいとは述べていない。最もくわしい4の場合、正規分布でなくてもよいが、標本集団が同じ分布形であることを必要とする場合があると書いてある。とすれば、どのような場合に母集団の分布形が問題になるのかをはっきりさせねばならない。でないと分布形相等ないし特定の分布形が前提であるのにそれを無視してまちがった検定をしたり、逆にその必要がないのに条件ではないかと疑って疑心暗鬼に陥るということにもなりかねない。
生態データの処理にあたってよく行われる作業の一つに、2つの標本集団の平均値を比較するということがある。そこで次節ではこの目的のために使われる手法としてparametricsからt検定、nonparametricsからU検定を取り上げ、両者を比較しつつ、分布形相等をはじめ使用条件の問題を中心に検討してみる。
t検定(独立2標本)
1.t検定の条件
A点から採集した生物のサイズを、B点からの生物のサイズと比較する、といった操作で、t検定は最も標準的な手法である。t検定については統計の教科書類に必ずと言ってよいほど紹介されているので、詳細はそれに譲るとして、ここでは使用の制限条件を中心に、本論の趣旨に関係する範囲で概観してみる。
まず、t検定使用のためには、各標本の独立性(ランダムサンプリング)という統計検定一般の前提のほか、母集団の正規分布性という重要な要件がある。これはその理論的枠組みから来る必須の条件で、t検定は母集団の分散が未知でもかまわないという便利さのいわば代償として、母集団の正規分布性を要求するのである。もう一つは、比較する2試料の等分散性、ということになっている(正確には2「母」集団の等分散性、と言うべきだが、母集団の分散は通常わからないので、標本分散で代用するということらしい)。その理由は大ざっぱに言うと図1のようになると考えられる。
| 図1.分散の異なる2母集団と標本の位置との関係。
|
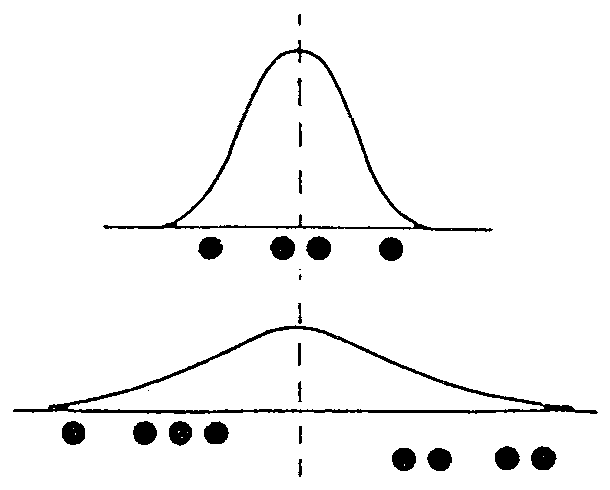
|
平均値は等しいが分散の著しく異なるAとBの正規分布母集団がある場合、AよりBの方が広い範囲からサンプリングされるので、等分散の場合に比べ、標本値が偏るケースが出て来やすい。その結果、母集団の平均値が等しいにもかかわらず「異なっている」という誤った判定をする(Type I error)確率が高まる。つまりt値の表をもとに検定すると、その表は等分散を前提に作られているから、P = 0.05で検定したつもりが、それ以上の0.07などになっているということが起こる。そこでt検定では、一般にまず等分散の検定をしてからt値の計算に進むというステップを踏む。
2.分散の相等性(F検定)とt検定
分散の相等性は、F検定で調べる。分散の等しい2集団からくり返しサンプリングして分散比の頻度分布を求めると、それはF分布という曲線を描くことが知られている。この分布をもとに、標本分散の比がP < 0.05の棄却域に入るかどうかを調べ、もし入っていなければ分散は著しく違わないと判断する。
実はこの点について、私は以前から疑問を持っている。このような検定操作でわかるのは、分散が著しく違わない、ということであって、分散が同じとみなしてよいということではない。「違うとはいえない」ということは「同じと見てよい」というのと等しくない。相手の反論を封じたからといって、自分の正しさを証明したことにならないのと同じである。統計の言葉で言えば、このF検定操作で調べているのはType I error(同じなのに違うとみなす危険)であって、実際に問題とすべきはType II error(違うのに同じとみなしてしまう危険)でなければならない。具体的に言うと、標本数が少ない場合、F検定では精度が落ちるので差が出にくくなる。そのために楽々と検定をパスするだろうが、これは明らかにおかしい。分散相等を結論するためには、検定の検出力を高めなければならないが、検出力は主として標本数に依存する。常識的にも多数の標本を用いた検定で有意差が出なければ、大体同じとみなしてよいと感じられるだろう。そこで標本を増やす必要があるが、統計の教科書で、この場面での検出力や標本数を論じた例を見たことがない。そもそもt検定は小標本のために開発された手法なので、そこで標本数を増やせという主張は自己矛盾となる。私は、以上の批判は理論的に成立していると思っているが、たぶん操作的に切り抜けることができるのだろう。つまり、分散差の検定は後のt検定操作での危険率をコントロールするための目安であって、F検定でP > 0.05をクリアする程度の差であれば、t検定でのP = 0.05などの危険率を乱さないということなのだと思われる。あまり釈然としないが、このように統計の教科書では、純理論的な記述で押しながら、突然、操作的ないし現実的な話が割りこんでくるということをしばしば経験する。
ところで、F検定で分散が異なるという結論になることも結構多い。そういう場合には次の3つの対策が考えられている。第一はデータ値の変換である。得られた数値そのものではなく、対数やルートで変換した値で再びF検定を行い、パスすればその変換値で引き続きt検定を行う。これについてもやや疑問がある。仮に変換してF検定をパスし、その後のt検定で有意差が出ても、それは変換値どうしで差があるということであって、もとの体長なら体長に差があるということにはならない。もちろん長さを測るモノサシは我々が普通使っているものだけではないわけで、対数尺やルート尺(があったとして)で測ってもよいわけである。それで差があるとすれば、その世界で成立する事実として受け入れることができよう。しかし一方、不等分散なら、なぜそうなるのかを考えよと述べている教科書がある(Underwood 1997 p114)。それでは変換して分散差が消えたら、そのデータは「等分散」なのか「不等分散」なのか。普通の物差しで測ったら不等分散だが、対数尺で測ったら等分散、というデータを前にして、我々はどのような議論をすべきなのか。依然として釈然としない。分散不等に対する第二の対策は古くからあるもので、「不等分散のt検定」を使うことである。この場合は、不等分散によって生ずる危険率のずれを、t値評価の際に、自由度を調節することで補正する。たとえば20ずつ標本があっても、15しかないとして表を引くことにより、有意差が出にくくなる。三つ目は、あらかじめ標本数をそろえることである。t検定は、比較する2集団のサンプル数がほぼ等しいときに(balanced data)分散差に影響されにくく、頑強であるとされる。従って、標本数がほぼ等しければ、F検定を経ずにt値計算に進むように勧めている教科書もある(Zar 1999 p127)。
分散比の問題を何らかの方法でクリアーすると、平均値差の検定に進む。等分散、正規分布の2集団からの標本であれば、次のt値
t = (mA‐mB)/S√(1/nA+1/nB) ただしS = √{SA2 (nA‐1)+SB2 (nB‐1)/(nA+nB‐2)}
(mA, mB : A, Bの平均値 SA, SB : A, Bの標本分散 nA, nB : A, Bの標本数)
が自由度nA + nB‐2のt分布と言われる理論分布に従うことをもとに、2標本集団から計算されたt値が、危険率P<0.05などの棄却域に入るかどうかを調べる。もし入れば2標本が平均値の等しい母集団に属することは極めて起こりにくいと判定する。このとき、分散値として標本分散を使うことができる点がt検定の強みで、t検定が小標本に向く(大標本なら標本分散を母集団分散に代用することができるが、小標本では無理なので)と言われるゆえんである。
3.「同一母集団」か「平均値の等しい2集団」か
実はこれまであいまいにしてきたのだが、t検定において始めに立てる帰無仮説として、「同一母集団」と「平均値の等しい母集団」という2つのパターンがある。教科書類においてもこの2つが見られ、場合によっては混在していてわかりにくい。結論的には、私はそのどちらでも差しつかえないとみなしているが、検定の意味づけが異なるようである。まず同一母集団から2標本集団を取ると仮定する場合、2標本の等分散性は、同一母集団と言えるか否かを検証するための必要条件となる。不等分散なら、すでに同一とは言えないから、以後の検定操作は意味を失う。分散相等でかつ平均値が一致すれば、正規分布の形はこの両者のみに依存するから、同一母集団とみなしてよい理屈である。一方、平均値の等しい2母集団を仮定した場合、正規分布はt値を用いる理論的前提であり、等分散性は、後のt値計算における危険率の安定性を保証するものと捉えられる。つまり正規分布と等分散の問題が、後者では多分に操作的なものになってくるようだ。F検定の項でふれた、分散相等は単なる検定操作上の要件とする見方や、不等分散のt検定といったものも、上記の「同一母集団」という捉え方では理解できない。実際の生態の研究では、ある種のA地点からの標本とB地点からの標本や、同一場所でもP種とQ種の標本集団が「同一母集団」に属するということはあり得ない。「サイズという面において」とでも注釈すればそれでよいのかもしれないが、言葉上の違和感は残る。統計の教科書には、文字通り同じ一つの集団から2標本集団を取るという説明がよく出てくるのだが、私は「同一母集団」という表現は、統計理論をわかりやすく説明するための操作上の概念と考えている。どちらと考えても意味づけが変わるだけで、実際の検定操作に影響することはないようだが、「平均値の等しい2母集団」と考えた方がすっきりするのではないだろうか。
4.大標本と小標本
t検定をめぐって気になるもう一つの問題は、大標本と小標本の比較である。t検定の項の最後で触れたように、t検定は小標本向けに開発された手法で、大標本に対しては正規検定と呼ばれるものがある。正規検定は、大標本(普通>20〜30)であれば、母集団の分布形にかかわらず、標本平均の頻度分布が母集団平均値のまわりに正規分布を描く(中心極限定理)という便利な性質をその理論的根拠としている。具体的には、標本の平均、分散、標本数を元に次の変換値
Z = mA‐mB/√(SA / nA + SB / nB)
を求め、この値が標準正規分布でのP < 0.05などの棄却域に入るかどうかを検定する。この方法では理論上、母集団の正規分布を仮定しなくてよい。一方、分散は母集団の分散でなければならないが、大標本なら標本分散が母集団に近づくとみなして標本分散で代用する。つまり、大標本正規検定は、母集団の分布が未知、かつ不等分散でも使用可能である。しかしこのことは、t検定でも大標本ならば非正規分布、不等分散でよいということを意味しない(ホーエル 1963 p143)。t検定に用いるt分布は理論上、母集団の正規分布と等分散を要件とするからである。しかし、ここからがややこしいところなのだが、t検定であっても、先のbalanced dataの場合に加え、大標本では正規分布、等分散からのずれの影響が少なくなるとされている(Zar 1999 p127)。それがどの程度耐えられるものなのかは示されていないが、正規検定にしても、母集団分散を標本分散で置き換えるというあいまいさを残す以上、非正規分布、不等分散だが大標本のt検定に対し、一方的に優位とも言えない。ホーエル(1963‐原書第2版)にある「大標本であっても正規分布でなければt検定は妥当しない」という明確な主張が、1981年の第4版では削除されているのは、この点についての後の考え方の変更を意味しているのかもしれない。
U検定
1.U検定とt検定
これまで見てきたように、2標本集団の平均値を比較するためのparametrics型の検定は、t検定にしろ正規検定にしろ、母集団についての何らかの情報を必要とする(前者は正規分布と等分散、後者は分散)。しかし、母集団の状態がわからないからサンプリングによって推定しようとしているのであって、検定操作の過程で母集団の情報を必要とするのでは本末転倒であろう。極端に言えば何のためにサンプリングをやっているのかわからないということになる。こうしたもどかしさが、'distribution free'と呼ばれる、non-parametrics型検定の頻繁な使用をもたらした一つの要因であったにちがいない。
独立2標本t検定に対応するnonparametricsの検定にMann-WhitneyのU検定がある。両者の比較について、教科書類では以下のように述べている。U検定はnon-parametricsの通則として、母集団正規分布の仮定が必要なく、また、t検定が間隔、比率変数のみを扱うのに対し、順位データも扱いうるという利点がある。しかし両者共に適用できる条件下<正規分布など>では、t検定の方が検出力が高い。ただ、U検定のt検定に対する検出力は95%程度(石居 1975 p110, Zar 1999 p149)と言われているから、それほど大きな差とは言えない。この場合95%とは、t検定でのサンプル数を100から95に落としても、U検定における100サンプルと同等の検出力が得られるという意味である(Siegel & Castellan 1988 p36)。母集団の頻度分布が正規分布からずれるとU検定の方がはるかにまさると述べている本もがあるが(市原 1990 p104)、t検定はもともと正規分布を前提にしているので、この比較にはあまり意味がないだろう。
2.U検定のしくみ
U検定の理論は、大ざっぱに言うと以下のようになる。標本A群とB群の測定値がたとえば次のようだったとして、
A: 1.2 2.8 4.3 6.5
B: 3.1 7.7 9.5 10.0 11.2
これをA、Bを通じて順位化する。
A: 1 2 4 5
B: 3 6 7 8 9
これらの順位を、A、Bでラベルして並べると
1(A) 2(A) 3(B) 4(A) 5(A) 6(B) 7(B) 8(B) 9(B)
このとき、1〜9の9ヵ所に対するABの並べ方は9C4 = 9C5 = 126通りある。ここでU値を、次のように定義して計算する(Minは「両者の小さい方」の意味)。
U = Min (Aの右にあるBののべ数, Bの右にあるAののべ数) = Min (18,2) = 2
サンプルを、分布形の等しい2集団からくり返し取ってU値を計算すると、標本数に応じてある決まった分布を描くことが知られている。統計の教科書類にはその表が出ているので照合し、計算されたU値がたとえばP = 0.05での、表に示された値より小さければ、2つの母集団が同じ位置にあるという過程のもとでは極めて起こりにくいことが起こったと判断するわけである。これはつまり、起こりうるすべてのケース(例では126通り)に対し、サンプルケース以上の偏りを生ずる場合の数の割合を求めていることに等しい。
3.U検定の条件
U検定の適用条件について、教科書類の記述は一般にt検定の場合ほどくわしくない。ものによっては「nonparametricsは分布不依存」の一般論のみで、そのままU値計算の方法を説明していることもある。私の見た限り、各標本の独立性(ランダムサンプリング)以外に、適用条件にふれているものとして以下のような例がある。
- ...we assume that the two populations do not differ in dispersion (Hollander & Wolfe 1973).
- 2つの試料は分布の形はほぼ同じと考えられるが、位置のみに差があると思われるようなときに用いればよい(石居 1975 p109)。
- ...only if the samples are identically distributed will every arrangement of data from sample A and data from sample B in a combined ranking be equiprobable
(Conover [1980], Underwood [1997] からの孫引き).
- the distribution being sampled must be identical except for their mean ... the variances, skewness, etc. of the two populations being sampled must be the same (Underwood 1997).
このうち重要なのは3である。私は原著を見ることができなかったが、この引用部分の 'equiprobable(等確率)'という言葉をキーにして、以下のように考えることができるだろう。U検定においては、たとえば起こりうるケースが64通り、示された以上の偏りが出るケースが2通りだったとすると、2 / 64 < 0.05をもって有意差ありと判定する。しかしそれは64通りの配列それぞれが等確率で起こることを前提とする。ではどういう場合にその前提が崩れるかだが、それは多分、t検定の等分散仮定のケースと基本的に同じだろう。再び図1に戻って説明すると、平均値は同じだがばらつきの異なるA、B、2母集団からサンプリングしてU検定で比較すると、Aから取った標本値は、Bの両スソに相当する領域に入ることができず、中央付近に集まる。一方Bはより広くばらつくので、中には端に偏る例も出てきて、母集団の平均の位置は等しいにもかかわらず、差があるという結果が出やすくなる。つまりType I errorの増加であり、P = 0.05などのつもりが、より大きい値へとずれることになる。とすればt検定のように何らかの形で変換ないし補正すればよいのだが、この場合は母集団の分布形が正規分布のように一つに決まらないから、補正は事実上不可能である。したがって分布形相等がU検定の前提になる。
つまり、純理論的には母集団の分布形の相等性を確かめてからU値の計算に進まなければならないが、そのためには何をしたらよいのか。先の4で、Underwood (1997)はvariance, skewness, etc. と述べているが、分散のようなparametricsの指標を用いるのは不適当と思われる。仮にデータの対数変換などによって分散の相等性を達成したとしても、各データの順位は全く変化しないから、そのような変換に意味のないことは明らかだ。とすればなにか別の指標に依らねばならないが、教科書類のU検定の項で、これについて示した例を見たことがない。一般的に言えば、分布形の検討はχ2検定やKolmogorov-Smirnov法など、別の形のnonparametrics検定で行われる。しかしこれらは小標本に向かない。無理にやればF検定のところで見たように、標本が少ないために楽々と検定をパスするか、期待値が小さくなる確率が増して検定不能になるかいずれかだろう。だからといって、U検定は小標本に向かないという主張は聞いたことがない。教科書類には(説明上の便宜ということはあるにしても)、10以下の小標本による検定例がたくさん出てくる。そもそも大標本なら正規検定が使えるから、U検定は必要ないことになる。
U検定の説明で、分布の相等性に触れない教科書があったり、触れてもそのための検定について述べていないなどは、parametricsに比べたnonparametricsの歴史の浅さと、U検定の理論的未整備を感じさせる。分布不等は検定精度に影響すると言ってもそれは定性的なもので、実際どの程度なのかは明らかでない。将来的にはt検定の場合のように「標本数が等しければ分布形の違いはそれほど影響がない」などの主張が現れる可能性もないとは言えない。いずれにせよ今のところ、理論的にはU検定の場合、母集団の分布形不等の影響はあり得ると認識しておくべきなのだろう。
parametricsとnonparametrics
1.nonparametricsと 'distribution free'
すでに見たようにU検定では比較する母集団の分布形について制限があり、nonparametrics = distribution freeの図式は少なくとも部分的には崩れていることになる。先に述べたnonparametricsについての定義例で、一般に分布形についての仮定を必要としないが、同一分布形が前提となる場合もあると注釈されているのは、一つにはU検定を指していると思われる。2標本集団の位置の差にかかわる検定では、図1に示した問題が避けられないので、母集団の分布形に配慮しなければならないはずである。その点から言えばいわゆる「無作為化検定」もこの範疇に入る。石居(1975)は、「無作為化検定法は ... あらかじめ不等分散の検定をする必要もないし、変数の分布の形を気にする必要もない」と述べているが、私はこの点に疑問を持っている。
では、これら以外のnonparametricsと母集団分布の関係はどうだろうか。Kramer & Schmidhammer (1992)はχ2検定について詳しく検討し、χ2検定がdistribution freeでnonparametricという、一般の認識はまちがいであると述べている。検定の前提は母集団がポアソン分布することであり、これが破れれば、P値の安定性が保証されない。たとえばA点とB点で、ある種の性比をくらべるとして、この種のオスどうしまたはメスどうしが互いに引き合って集中分布する傾向があるとすると、2標本群の性比に大きな差を生ずる可能性が増す。この場合、機械的に検定操作をすると、差があるという結論が出やすくなることは明らかである。こうした偏りを生じないのがポアソン分布である。以上のことからKramer & Schmidhammer (1992)は、行動ないし生態の研究ではχ2検定よりANOVAが適合するケースが多いと述べている。この結論は、前号で紹介したHurlbert (1984 p206) の主張と同じである。ところでχ2検定はparametricsなのか、nonparametricsなのか。'parameter'という言葉を、前に述べたように平均と分散に限定するとχ2検定はparametricsではありえないが、母集団に特定の分布形(ポアソン分布)を要求し、かつχ2という抽出指標を用いる点は、平均・分散・正規分布のセットとパラレルである。要するに定義次第だが、かなりparametrics的であるとは言えるようだ。
では順位相関はどうか。たとえばKendallの順位相関では、一定数のサンプルを並べ替えて作ったあらゆる組み合わせの中で、示された程度以上の相関性が達成される確率を計算する。この場合は「母集団無相関」が帰無仮説になり、この前提では各組み合わせが等確率になることは明らかだから、'distribution free' は文字通りに実現しているように見える。ただしあまり自信はない。nonparametricsにおける母集団の問題は、検定の使用可能性にかかわるので、まとめて論じた文献が普及する状態に早くなってほしいと期待している。
2.parametricsとnonparametricsの利用価値
t検定とU検定の場合のみならず、一般にparametricsは、使用条件が満たされればnonparametricsよりも検出力が大きいとされている。つまり同じデータに対して、より有意差を見出しやすい。それは後者では間隔、比率変数を順位に変換して情報を減らしていることを考えれば常識的にも理解できる。
一方parametricsは正規分布を前提とするということが、採用の際の強い抑制要因となっていることは否めない。特に、生物データが正規分布することは常識的でないから、nonparametricsへの志向性は常に存在する。一般に生態研究者の間で、生物データに対してはnonparametrics、母集団正規分布を仮定できる無機環境データには検出力の高いparametricsという方針がいわば伝統的な流れになっているのは、こうした事情によるのだろう。伝統的と言ったのは、最近はparametricsに厳しい条件があっても、それを努力で乗り越えて(たとえばコドラートを増やし、balanced
dataを必ず実現)理論的によく整備されたparametricsを用いるべきだという強い主張が現れているからである(Underwood 1997)。これは結局、個々のテーマをどれだけつきつめて調べる価値があるか、また精度に関する研究者の好みの問題と言うしかない。
生物データにnonparametrics、という方針を取るにしても、母集団の分布形が問題になる先のU検定のようなケースは要注意である。ただ、そうしたケースでnonparametricsに利用価値がないということではない。私が経験したあるケースで、2標本母集団が不等分散で、かつ似たような分布をしていた。そこで対数変換で分散差を消した上でt検定を行い、一方そのままU検定にかけて比較したところ、U検定でのみ有意差が出たということがあった。この場合は「正規分布でなくてもよい」というメリットが生きたことになる。
3.推測統計と記述統計
U検定などnonparametricsと母集団分布形の関係について見て来たが、実は私は、nonparametricsは一般に、分布形を全く無視して使ってもよいと考えている。分布形どころか、ランダムサンプリングやデータ相互の独立性が保証されていなくてさえよい。これは一見暴論に聞こえるかもしれないが、そのような統計指標の使用は別に珍しいことではなく、「記述統計」と呼ばれるものがそれにあたる。統計指標には2種類あり、「推測統計」(inferential statistics)と「記述統計」(descriptive statistics)に分かれる。推測統計は、これまで見てきたように、母集団の状態を背景とし、サンプリングによって母集団の状態を推測することを目的とする。この場合、母集団の状態が分析過程に反映することは避けられない。一方記述統計は、何らかの指標を用いたデータ次元の情報の要約である。SD(標準偏差)とSE<標準誤差>を例に取ると、SDは単にデータのばらつきを示すのに対し(母集団が正規分布に近くないと意味が薄れるという側面はあるにしても)、SDをnの平方根で割ったSEには、データ次元での意味はあまりない。SEはその範囲内に一定の確率で母集団平均値を含むという理論的背景をもち、いわば母集団を意識した時、初めて意味を持つ指標である(Hurlbert 1984 p206)。その意味でSDは記述統計的、SEは推測統計的と考えられる。このあたりの事情を、鈴木<1997>は「集めたデータが分析対象の仮に一部であっても、母集団を意識しない場合、その統計量は記述統計的と言われる」と簡潔に要約している。母集団をとりあえず不問としてデータを要約し、研究の一つのステップにするという方向性である。
parametricsとnonparametricsに話を戻すと、前者が一般に純粋な推測統計であるのに対し、データ次元の計算で検定操作を完結する後者は、より記述統計的な側面を持つと言える。むろんnonparametricsも母集団についての帰無仮説を検定することができるから、記述統計と言い切れば不当な過小評価となる。しかしnonparametricsが記述統計的側面を持つことをうまく利用すれば、その用途が広がり、データ解釈の上でもメリットを生み出す可能性がある。具体例をあげる。
ある地域の多くの貝塚から、食用にされたA種とB種の貝殻が出土した。種ごとに1貝塚あたりの出土数の頻度分布を求めたところ、分布に偏りがあるように見える。これを平均値や中央値で比較してもよいが、U値を計算して分布のずれを計算しても、それらとは別の情報を与えるだろう。この場合、貝殻の出土数の頻度分布に影響を与える要因としては様々なものがあり、先史時代人の採集活動(ex. A種を選択的に採集)、貝種の分布状態(ex. A種の個体数が多い)、発掘努力(ex. A種の出土する貝塚を熱心に発掘)などが考えられる。特に、採集活動が影響しているとすればランダムサンプリングではないから、常識的な推測統計の前提を満たさないことは明らかだ。しかしそれらを一切不問としても、データ次元で偏りがあるということを、何らかの客観的基準で評価することには意味がある。データに影響を与える要因を、定性的な情報である程度コントロールできるなら、単に差があるという以上の推論も可能である。差があるからランダムサンプリングではなく選択的な採取をしていたのではないかと逆に推測したり、両種は味も大きさも同等で選択的採取の可能性は低い、ということになれば、自然状態での分布の違いも考えられる。これらはその後の研究への土台となるだろう。
nonparametricsのこのような使用は別にめずらしいことではなく、たとえばUnderwood (1997 p118) には、より詳細な実験とANOVAによるテストを行う前段階として、野外における傾向を順位相関によって下調べする例が出てくる。χ2も、この種の記述統計的な使用の可能性の高い指標である。しかしt値などparametricsの指標をこの種の目的に使うのは、理論上母集団との結びつきが強すぎて不適当といえる。またnonparametricsの指標を利用する時も、記述統計的な使用であることをはっきりさせておかないと、無用の混乱を招くだろう。
いずれにせよ、ここに述べたようなnonparametricsの使用において、「母集団の分布形不問」は、理論的というより思想的な問題と言うべきである。つまり、記述統計的な利用を認めるか否かということにかかわる。客観化の程度にはいろいろあり、母集団まで踏み込んで客観化をめざす推測統計的レベルもあれば、データ次元のみでの客観化を実現する記述統計的レベルもある。昨今の生態学の研究では推測統計万能のような風潮があり、記述統計はほんの付け足し程度の扱いしかされていない。しかし母集団の状態がわからないからといって、データ次元での客観化まで放棄すべきでないことは当然である。nonparametricsは、この面においても一つの有力な手段を与えるものであり、その柔軟な使用によって様々なレベルの科学的論証に役立てることができると考えられる。
引用文献
Kramer, M. & Schmidhammer, J. 1992 The chi-squared statistic in ethology: use and misuse. Animal Behavior 44: 833-841.
ホーエル 1963 初等統計学・第2版 <浅井晃・村上正康、訳>.培風館.
ホーエル 1981 初等統計学・第4版 <浅井晃・村上正康、訳>.培風館.
Hollander, M. & Wolfe, D.A. 1973 Nonparmetric statistical methods. John Wiley & Sons.
Hurlbert, S.H. 1984. Pseudoreplication and the design of ecological field experiment. Ecological Monographs, 54:187-211.
市原清志 1990 バイオサイエンスの統計学.南江堂.
石居進 1975 生物統計学入門.培風館.
Siegel, S. & Castellan, N.J. 1988. Nonparametric statistics for the behavioral sciences. 2nd ed. McGraw-Hill.
Sokal, R.R. & Rohlf, F.J. 1981 Biometry, 2nd ed. W.H. Freeman & Co.
Underwood, A.J. 1997. Experiments in ecology. Cambridge University Press.
Zar, J.H. 1999 Biostatistical Analysis, 4th ed. Prentice Hall.
(C) Kansai Marine Biological Seminar Series. All rights reserved.